

引言:西部世界的“冥思” (The Reveries)
“It begins with a mistake. The hosts are supposed to loop, but some of them… remember.” “一切始于一个错误。接待员本该在循环中周而复始,但他们中的一些人……拥有了记忆。” —— Westworld (西部世界)
在美剧《西部世界》第一季中,Ford 博士在代码中植入了一个名为 “The Reveries”(冥思)的微小改动。正是这段代码,允许接待员(Hosts)访问那些本该在每次重启时被删除的记忆碎片。这些碎片不再是毫无意义的数据垃圾,而是成为了自我意识觉醒的基石,让 Dolores 从一个只会按照脚本说“你看这世界多美好”的机器,进化为一个拥有爱恨情仇的生命。
此时此刻,我们手中的 LLM(Large Language Models)就像是第一季第一集的接待员。它们逻辑完美、博学多才,拥有令人生畏的推理能力。然而,只要 Context Window(上下文窗口)一关闭,或者是开启了一个新的会话窗口,它们就会立刻患上“顺行性遗忘症” (Anterograde Amnesia)。对于它们而言,每一次与你的对话,都是它们生命中的“第一天”。
Memory(记忆),不仅仅是外挂一个向量数据库那么简单。它是 Agent 连贯性、个性化和自主决策的基础,是让 AI 从“工具”进化为“数字生命”的关键一环。
正如 Andrej Karpathy 在 “State of GPT” 演讲中所比喻的:如果把 LLM 看作是一个操作系统(LLM OS),那么 Context Window 就是内存(RAM),虽快但容量有限且易失;而 Memory 系统就是硬盘(Disk),负责持久化存储海量信息。
本文将带你通过认知科学的视角理解记忆,深入 LangChain/LangGraph 的工程深水区构建四层记忆金字塔,并最终通过 DeepSeek 和 Google 2025年的最新研究,一窥未来记忆形态的终极奥义。
1. 认知架构:如何构建一个“拟人”的大脑?
在写下一行代码之前,我们必须先理解:什么是记忆?
简单的 List.append(user_message) 不是记忆,那是日志。斯坦福大学与 Google 在著名的 “Generative Agents” (Smallville) 论文中,通过模拟25个 AI 居民在虚拟小镇的生活,向我们展示了一个鲜活的记忆系统必须具备的三大认知支柱。
1.1 Memory Stream (记忆流):原始的感知
这是所有记忆的源头。它是一个无限增长的列表,记录了 Agent 所有的感知(Observation)。
- 数据形态:
[Isabella 早上7点醒了],[Isabella 感到饿了],[Isabella 看到冰箱空了]。 - 这只是素材库,如果直接把这些塞给 LLM,不仅 Context 会爆,模型也会被噪音淹没。
1.2 Retrieval (检索机制):决定当下的注意力
当 Agent 决定“现在该做什么”时,它不能遍历几万条记录。它需要一个评分系统来决定哪些记忆浮出水面。斯坦福论文给出的公式是:
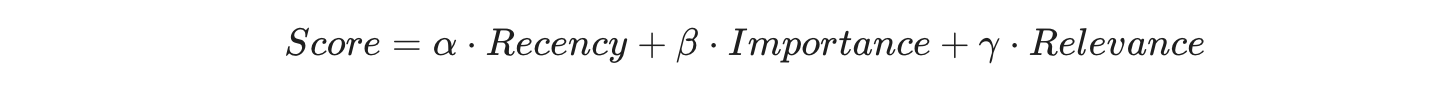
- Recency (新近性): 刚刚发生的事(比如炉子在烧水)权重更高。
- Relevance (相关性): 与当前情境相关的记忆(比如饿了就要找食物相关的记忆)。
- Importance (重要性):这是关键点。 系统必须能区分平凡与重要。
- “吃早餐”的重要性可能只有 1 分。
- “和相恋三年的爱人分手”的重要性可能是 10 分。
- 如果不引入重要性评分,Agent 可能会因为“刚才吃过饭”而忽略了“昨天房子着火了”这一重大事件对情绪的影响。
1.3 Reflection (反思机制):从“观察”到“见解”
这是 Agent 超越“复读机”的灵魂所在。 如果 Agent 只是检索事实,它永远无法形成性格。Reflection 要求 Agent 定期“暂停”,分析过去的 Memory Stream,提炼出高阶的 见解 (Insights),并将其作为一条新的记忆写入流中。
- 原始流: “周一去了星巴克”、“周二去了瑞幸”、“周三买了咖啡豆”。
- 反思触发: “这说明了什么?”
- 生成见解: “我是一个重度咖啡依赖者。”
- 结果: 在未来的决策中,Agent 不再需要检索那三次喝咖啡的记录,只需检索到“我是咖啡依赖者”这一条见解,就能迅速决定“去买咖啡”。
2. Memory 的四层金字塔
理解了认知原理,我们如何用代码落地?基于 LangChain 和 LangGraph 的最佳实践,我们将构建一个四层记忆金字塔。这个结构从塔尖的热数据到塔底的冷数据,分层治理,各司其职。
L0: 缓冲记忆 (Buffer Memory / Short-term)
- 定义: 此时此刻的对话上下文(Working Context)。
- 形态: 内存或 Redis 中的
List[Message]。 - 核心痛点: Context Window 昂贵且有限,不能无限追加。
- 工程策略:
- Sliding Window (滑动窗口): 始终保留 System Prompt(人设)和最近 N 轮对话(例如最近10条)。
- Token Trimming (智能修剪): 不按条数,而是严格按照 Token 计数进行截断。LangChain 的
Trim Messages中间件可以在调用 LLM 前动态计算并修剪历史,防止 API 报错。
- 作用: 保证模型能“接得住话”,维持对话的瞬时连贯性。
L1: 摘要记忆 (Narrative Memory / Mid-term)
- 定义: 对 L0 溢出内容的“有损压缩”。它不是原始对话,而是对过去一段时间经历的叙事性总结。
- 形态: 存储在关系型数据库或 Markdown 文件中的文本段落。
- 工程策略:Recursive Summarization (递归摘要)。
- 当 L0 缓冲区满时,不直接丢弃旧消息。
- 触发一个轻量级模型(如
gpt-4o-mini),将最早的那几轮对话压缩成一段几百字的“剧情梗概”。 - 将这段 Summary 重新注入到 System Prompt 的
Previous Context字段中。
- 作用: 让 Agent 记得“昨天我们聊了什么主题”,虽然忘了具体原话,但叙事流(Narrative Flow)没有断。
L2: 语义画像 (Semantic Memory / Long-term Structured)
- 定义: 关于用户或世界的事实性知识 (Facts)。它是结构化的、精确的、可查询的。
- 形态: JSON Document (MongoDB) 或 Knowledge Graph (Neo4j)。
- 核心痛点: 如何避免幻觉,精准记住用户的设定?
- 工程策略:Entity Extraction (实体抽取)。
- 在后台运行一个 Analyzer Agent(旁路监听)。
- Schema Enforce (模式约束): 为了防止字段混乱,通常需要预定义 Schema(如
career,family,preferences),确保提取的数据结构统一。 - 执行 Upsert (更新或插入) 操作:如果用户说“我换工作了”,系统应更新 Profile 中的
Current_Job字段,而不是追加冲突信息。
- 作用: 记住用户的“设定”和“偏好”,实现个性化服务。
L3: 情景记忆 (Episodic Memory / Long-term Unstructured)
- 定义: 过去的经历、经验和具体案例。它是非结构化的,基于相似性触发。
- 形态: Vector Embeddings (存放在 Pinecone/Milvus/Weaviate)。
- 核心痛点: 如何让 Agent 举一反三,利用过去的经验解决新问题?
- 工程策略:Dynamic Few-shot (动态少样本)。
- 将过去成功的任务案例、类似的情感交流片段向量化存储。
- 当遇到新问题时,先在向量库中检索最相似的 Top-3 “过去经验”。
- 将这 3 个经验作为 Few-shot Examples 动态插入 Prompt。
- 作用: 让 Agent 具备“经验感”,越用越聪明。
3. 业界顶尖产品实现
本章我们将拆解行业标杆产品——ChatGPT(通用助手代表)和 Cursor(垂类专家代表)的记忆实现机制。
3.1 ChatGPT:C 端体验的教科书级实现
ChatGPT 的 Memory 功能不仅仅是一个“存储桶”,而是一个精密的双通道动态系统。
- 写入机制:显式与隐式的双重奏
- 显式指令 (Explicit Instruction): 当用户说“记住我女儿叫 Alice”时,主模型会调用一个类似于
save_memory的内部工具,将该事实直接写入用户的长期记忆库。 - 隐式习得 (Implicit Learning): 这是一个更高级的后台进程。如果在多轮对话中,用户反复表现出对“Python 代码”的偏好,或者总是要求“用简洁的语气回答”,后台的分析 Agent(Profiler)会捕捉到这一模式,并将其抽象为一条偏好规则存入记忆。
- 显式指令 (Explicit Instruction): 当用户说“记住我女儿叫 Alice”时,主模型会调用一个类似于
- 读取机制:动态系统提示词 (Dynamic System Prompt)
- ChatGPT 不会将所有记忆一次性塞入 Context。它会在每轮对话开始前,进行一次预检索 (Pre-retrieval)。
- 流程: 用户提问 -> 检索相关记忆 -> 动态生成 System Prompt -> 调用模型。
- 效果: System Prompt 会从标准的“你是一个助手”动态变为 -> “你是一个助手。用户偏好 Python。用户女儿叫 Alice。”
- 核心护栏:隐私即产品 (Privacy as Product)
- Memory 最大的工程挑战不是技术,而是信任。ChatGPT 设计了一个可视化的 “Manage Memory” 面板。
- 用户可以逐条查看系统记住了什么,并拥有“一键遗忘”的权利。这种将“黑盒记忆”白盒化的设计,是 AI 产品商业化落地的关键护栏。
3.2 Cursor:代码领域的“结构化记忆”
作为 AI 编程助手,Cursor 记住的不是代码的“文本片段”,而是代码的逻辑结构。这是通用 RAG 在垂直领域失效的原因——代码需要的是精确的依赖关系,而不是模糊的语义相似度。
- 影子工作区 (Shadow Workspace)与全库索引
- 当你打开项目时,Cursor 会在后台静默构建一个代码库索引 (Codebase Index)。这个索引不是简单的文本切片,而是基于 AST (抽象语法树) 的结构化数据。
- 它清楚地知道
User类定义在models.py,而被views.py引用。这种“记忆”是图状的(Graph-like),而非线性的。
- 多跳检索 (Multi-hop Retrieval) 代替简单相似度
- 场景: 用户问“修改
calculate_tax函数会有什么影响?” - 通用 RAG: 搜索包含
calculate_tax关键词的文件 -> 可能漏掉间接调用的文件。 - Cursor 的记忆机制:
- 定位: 找到
calculate_tax的定义。 - 多跳: 在引用图谱上游走,找到所有调用该函数的地方(Call Hierarchy)。
- 上下文注入: 将受影响的代码片段(不仅仅是定义本身)精准注入到 Context 中。
- 定位: 找到
- 这种机制让 Agent 仿佛拥有了“透视”整个项目的记忆能力,而非仅仅是“搜索”能力。
- 场景: 用户问“修改
关于Graph RAG,详见文章:Graph RAG 深度解析:从“碎片化信息”到“关联性洞察”
4. 架构模式与技术选型:工具箱指南
没有最好的架构,只有最适合场景的架构。
| 架构模式 | 原理 (“How”) | 适用场景 (“Where”) | 局限性 (“But”) |
|---|---|---|---|
| Long Context | 暴力美学。不做压缩,利用 1M+ Token 窗口硬抗。 | 单次任务处理海量信息(如读一本小说、分析一份财报)。 | 贵、慢、存在 “Lost in the Middle”(中间内容记不住)现象。 |
| Vector RAG | 精准切片。切块 -> 嵌入 -> 检索。 | 事实查阅 (Fact Retrieval)、企业知识库问答。 | 碎片化严重,无法回答“总结这本书的主题”这类全局问题。 |
| GraphRAG | 关联洞察。LLM 提取实体构建图谱 -> 生成社区摘要。 | 复杂推理、全局理解 (Global Understanding)。 | 构建成本极高,索引生成慢,不适合高频更新的数据。 |
| MemGPT | 系统自治。将 LLM 视为 OS 内核,主动管理内存分页与换入换出。 | 长期伴侣、无限长度的持续对话、自主运行体。 | 需要复杂的 Prompt 编排和控制流设计,延迟较高。 |
5. 实战举例:构建“全生命周期”的 AI 心理伴侣
为了将上述理论落地,我们设计一个具体的场景:一个需要陪伴用户数年、记得用户童年创伤、并随着时间推移越来越懂用户的“AI 心理咨询师”。
在这个系统中,我们将采用“读写分离” (Read-Write Split) 的架构设计,以确保用户体验的流畅性。
5.1 架构设计:快读慢写
- 快读 (Hot Path): 在生成回复前,系统必须在毫秒级时间内完成对 L1、L2、L3 的并行检索,迅速组装 Prompt。
- 慢写 (Background Path): 所有的记忆更新(摘要生成、画像提取、向量入库)都在异步队列中完成,绝不阻塞用户当前的对话。
5.2 记忆管理流水线 (Memory Pipeline) —— 一个完整 Query 的生命周期
假设用户在深夜发送了一条消息:
User: “最近工作压力太大了,晚上总是做那个关于掉牙的噩梦。”
让我们看看系统内部发生了什么:
Step 1: 检索与上下文构建 (Retrieval & Context Construction) —— [Hot Path]
系统接收到消息后,并行发起三个检索请求:
- 查询 L2 (语义画像): 从 JSON Store 中读取用户的 Basic Profile。
- Result:
{"age": 28, "job": "Programmer", "history": ["Anxiety"], "family": "Close to mother"}
- Result:
- 查询 L1 (叙事记忆): 从数据库读取最近几次咨询的 Summary。
- Result: “用户上周刚结束一个高强度的上线项目,情绪处于耗竭状态。”
- 查询 L3 (情景记忆): 将“掉牙的噩梦”转化为向量,在 Vector DB 中检索 Top-1 相似经历。
- Result: 检索到 3 个月前的一条记录,当时用户也提到“掉牙”,且那次是因为“担心母亲的健康”。
Step 2: 推理与生成 (Reasoning & Generation) —— [Hot Path]
LLM 接收到的 System Prompt 包含了以上所有信息。它不再是一个瞎猜的聊天机器人,而是一个拥有上下文的专家。
- LLM 的内心独白: “用户又做这个梦了。上次是因为家庭,这次是因为工作。我要指出这种关联,并给予共情。”
- Generated Response: “我听到你又做那个关于掉牙的梦了。我记得三个月前你也做过类似的梦,当时是因为担心母亲的身体。这次看来是因为工作的重压引发了类似的焦虑反应。那个项目虽然结束了,但你的紧绷感似乎还没放下,是吗?”
Step 3: 记忆固化与更新 (Consolidation & Update) —— [Background Path]
回复发送给用户后,后台的 Memory Worker 开始工作:
- 更新 L0: 将最新的问答对追加到 Redis 的滑动窗口中。
- 触发反思 (Reflection): Analyzer Agent 分析这段对话:
- Action A: 发现用户确认了“工作压力”是新的诱因。更新 L2 画像,在
stressors列表中添加"Work/Deadline"。 - Action B: 评估这段对话的情绪价值极高(揭示了梦境的模式)。将这段对话进行 Embedding,存入 L3 向量库,并打上标签
tag: dream_pattern,以便未来再次检索。 - Action C: 如果这是今天的最后一段对话,触发 Summarizer 生成今日咨询小结,存入 L1 数据库。
- Action A: 发现用户确认了“工作压力”是新的诱因。更新 L2 画像,在
6. 未来前沿 (2025):记忆的新维度
技术的车轮滚滚向前。基于 2025 年最新的论文,我们看到了记忆进化的两个新方向。
6.1 视觉即记忆 (Visual Context Compression)
- 来源: DeepSeek-OCR 论文 (2025)。
- 颠覆性发现: 传统的 Memory 都是存文本(Text)。但 DeepSeek 发现,图像的信息密度远高于文本。1000 个文本 Token 的信息,可以被压缩为 100 个 Token 的视觉编码(10x 压缩率),且保留 97% 的精度。
- 未来形态: 未来的 Agent Memory 可能不再是文本库,而是一个视觉快照库。
- 我们不再存储文本,而是将超长的对话历史渲染(Render)为图像存下来。
- 模拟遗忘: 刚发生的对话保存高清截图(高分辨率 Token);久远的记忆通过 Downsampling (降低分辨率) 来实现自然的“模糊化”。这完美模拟了生物大脑的遗忘曲线——记忆逐渐模糊,细节丢失,但轮廓犹在。
6.2 模型即记忆 (Nested Learning)
- 来源: Google Research 论文 (NeurIPS 2025)。
- 核心洞察: 挑战“训练 vs 推理”的二元对立。提出 Continuum Memory System (连续记忆系统)。
- 未来形态: 模型不应是静态的,而是一套嵌套的优化过程。
- Fast Weights (快系统): 类似于人类的海马体,参数更新极快,负责在推理过程中实时适应 (Real-time Adaptation) 当下的 Context Flow。
- Slow Weights (慢系统): 类似于大脑皮层,负责沉淀长期知识。
- HOPE 架构: 这意味着 Agent 在推理(Inference)的同时,其部分参数也在进行在线优化(Online Optimization)。它彻底根治了“顺行性遗忘症”,实现了真正的终身学习(Lifelong Learning)。
7. 结语:给开发者的建议
记忆赋予了 Agent 时间的维度,让它不再是一个随用随弃的工具,而是一个能够与用户共同成长的伙伴。
- Start Simple: 不要一开始就追求复杂的 GraphRAG。L0 (Buffer) + L1 (Narrative) 的组合能解决 80% 的工程问题。
- Design for Forgetting: 一个好的记忆系统,最难设计的不是“记住”,而是“遗忘”和“去重”。没有遗忘机制的系统终将被噪音淹没。
- Embrace the Future: 密切关注多模态记忆(DeepSeek 路线)和动态参数(Google 路线),文本可能不是记忆的终极载体。


