

仅仅在一年多以前,AI 图像生成还像一个“高级玩具”。它充满了难以攻克的“顽疾”:画不出正常的手指、无法在图像中渲染出准确的文字、更难以在不同画面中保持同一个主体(如人物或风格)的一致性。
而今天,从 DALL-E 3 到 Midjourney 和 Stable Diffusion 的最新迭代,这些问题在很大程度上已被逐一攻克。AI 产出的作品已经达到了照片级、高保真的水准,AIGC 正在从“玩具”高速进化为“生产力工具”。
这些看似“魔法”的工具,其技术基石并非无法理解的“黑匣子”。它们都构建在一个统一且强大的核心框架之上:扩散模型(Diffusion Model)。
这个核心过程,类似于调谐一台老式收音机或黑白电视。我们想要的图像是一个清晰的“电台信号”,但它被埋藏在巨大的“白噪声”中。AI 的工作,就是从 100% 的纯噪声(“沙沙”声、雪花屏)开始,在提示词(“目标频率”)的引导下,一步步“调谐”旋钮,将“信号”从“噪声”中恢复出来。
本文将深入拆解这一“从混沌中恢复秩序”的核心原理,分析主流工具(DALL-E VS Midjourney/Stable Diffusion)在实现路径上的关键差异,并解构“文生图”和“图生图”的完整工作流,以及我们如何通过关键参数来操纵模型生成。
一、扩散模型:“从混沌中恢复秩序”的核心思想
所有扩散模型,都源于一个看似矛盾的物理过程:有序的图像可以变为纯粹的无序(噪声),那么这个过程能否被逆转?
扩散模型通过两个阶段来回答这个问题:
- 前向过程(加噪): 这是一个固定的数学过程。它从一张清晰的原始图片开始,在几百上千个“时间步”(timestep,即一个极小的时间片段)中,逐步向图片中添加微量的“噪声”(Gaussian Noise,高斯噪声,一种形态最标准、最随机的静态噪点)。最终,这张图片会彻底变成一张完全随机、毫无意义的纯噪声图。

- 反向过程(去噪): 这是 AI 学习的核心。我们训练一个神经网络模型,让它“观察”前向过程。AI 的任务是预测在任意一个“时间步”
t,被添加到图片中的噪声到底是什么。
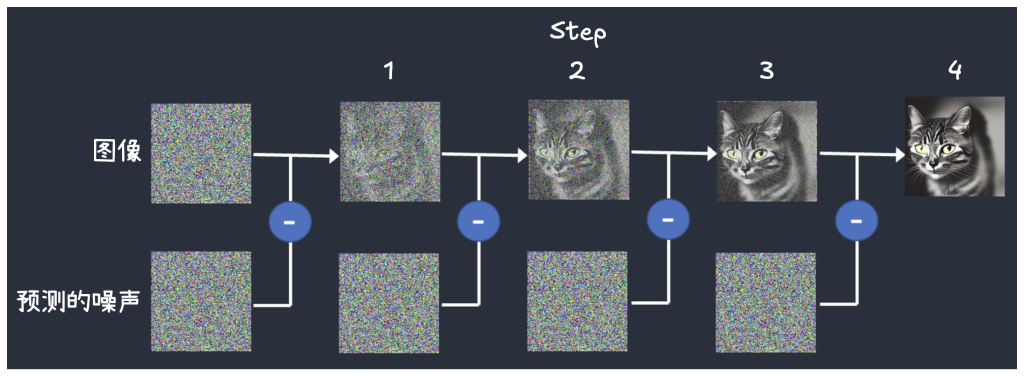
训练完成后,这个神经网络就成了一个强大的“噪声预测器”( 发散:LLM 预训练得到的基础模型,是一个“Token预测器”,见“大语言模型(LLM)训练的三个阶段” )。
AI 绘画的本质,不是“从白纸作画”,而是“从混沌(噪声)中逐步恢复出秩序(图像)”。
“反向过程(去噪)”听起来很神奇,AI 到底是如何“学会”去噪的?我们可以用一个视觉化的方式来理解。
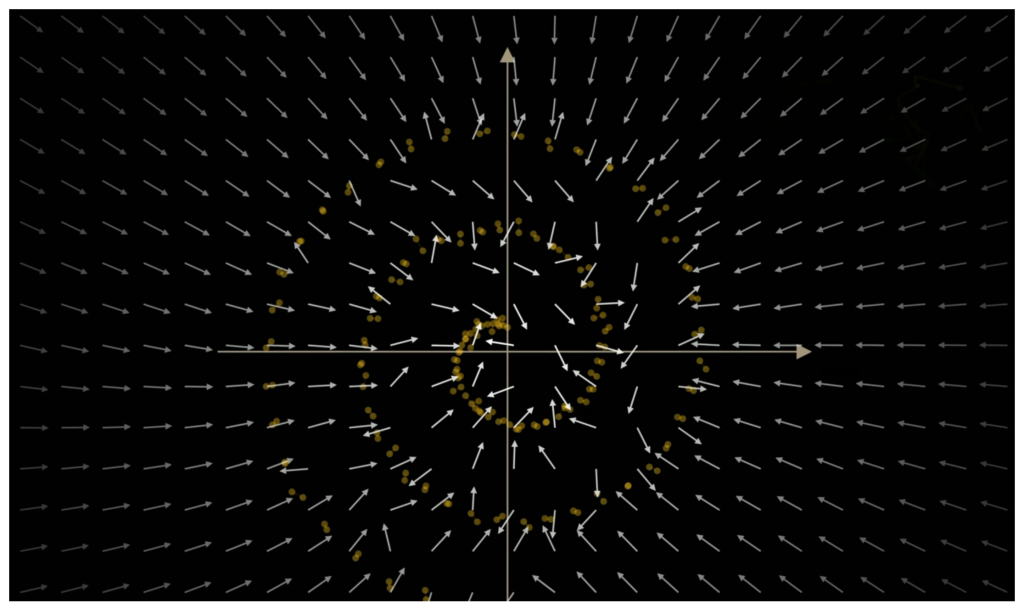
想象一个巨大无比的“像素仓库”(即“高维空间”,一张由一组像素组成的图片,在该空间内就是一个点),理论上它包含了“所有”可能的像素组合。但这个仓库里 99.999% 的“点”都是毫无意义的“电视雪花点”(纯噪声)。
- “真实图像”的“家” (流形 – Manifold): 所有“真实且有意义”的图像(全世界的猫、狗、风景)在这个“像素仓库”中并非随机散落,而是紧密地聚集在一个特定区域,形成一个极其复杂的结构化“形状”。这个“形状”在数学上被称为“流形”(Manifold)。
- 简单来说: “流形”就是所有“好看图片”的“家”。在“家”之外,就是“噪声”的“荒野”。
- 前向过程的意义: “加噪”的过程,就像从“家”(流形)里任意一个点(例如一张猫的照片)出发,然后通过“随机游走”,一步步将它踢向“荒野”(噪声空间),直到它彻底迷失。
- 反向过程的目标 (向量场 – Vector Field): AI 的训练目标,就是创造一张覆盖整个“仓库”(包括荒野)的“回家地图”。这张“地图”在数学上被称为“向量场”(Vector Field)。
- 简单来说: 这张“地图”上布满了无数的“箭头”(向量)。无论你身处“荒野”中的哪个位置(例如一张 90% 噪声的图),这个“地图”总会为你提供一个“箭头”,告诉你“回家(流形)的最近路径该往哪走”。
当我们命令 AI“生成一张新图”时,整个过程如下:
- 我们先把 AI “扔”到“荒野”中的一个随机位置(即生成一张纯噪声图)。
- AI 打开它的“回家地图”(向量场),查看当前位置的“箭头”指示。
- AI 顺着“箭头”走一小步(即执行一次去噪)。
- 它会重复这个过程几十次(即采样步数),直到“地图”指引它一步步“走回”了“家”(流形)的边界。
它“降落”在“家”上的那个点,就是一张全新的、有意义的、从噪声中“导航”回来的“真实图像”。
二、AI 绘画的原理:一个原理,两种实现路径
虽然核心思想都是“去噪”,但主流模型在“如何实现去噪”这一关键问题上,选择了不同的技术路径,这直接决定了它们的性能和可访问性。
路径一:“潜空间”派(Stable Diffusion & Midjourney)
这是目前最主流且最高效的实现,被称为潜空间扩散模型 (Latent Diffusion Model, LDM)。
- 核心挑战: 扩散模型的核心挑战是计算量。一张 512×512 的彩色图片有超过 78 万个维度 (dimensions,即每个像素的R/G/B颜色值都是一个可变维度),在如此多维度的“像素空间”中直接去噪,计算成本极其高昂。
- LDM 解决方案: LDM 巧妙地引入了一个“压缩”步骤。它不直接处理像素,而是在一个被高度压缩的、更小的“潜空间” (Latent Space,一个只包含核心“摘要”信息的压缩空间)中完成所有去噪工作。
LDM 的训练与组件:
LDM 架构的训练,依赖于包含了数十亿“图像-文本”配对的庞大数据集(如 LAION-5B)。模型在训练中学习的,就是“图像内容”与“文本描述”之间的关联。这套架构的训练,是依赖多个“预训练模型”协同工作的:
- 组件一:VAE (变分自编码器)
- 作用: 这是一个独立预训练的模型,专职负责“压缩”和“解压”。
- 编码器 (Encoder): 负责将 512×512 的像素图,压缩成 64×64 的潜空间“摘要”。
- 解码器 (Decoder): 负责在生成图片的所有工作完成后,将 64×64 的“摘要”解压,还原成 512×512 的高清像素图。
- 状态: 在 LDM 的核心训练中,VAE 是冻结的,只作为一个高效的“转换工具”使用。
- 组件二:CLIP 文本编码器
- 作用: 这也是一个独立预训练的庞大模型,它本身就是在“图像-文本”配对数据上训练的,专职负责“翻译”文本。它将“提示词”(Prompt)——无论这个词是来自训练集的“标题”,还是来自用户的“输入”——都翻译成 AI 能理解的“数学向量”。
- 状态: 在 LDM 训练中,CLIP 也是冻结的,只作为“指令”的来源。
- 组件三 (核心预训练模型):U-Net (噪声预测器)
- 这才是扩散模型真正“训练”的核心。 它的训练就是我们上文提到的“反向过程”。
- 训练步骤如下:
- 取一张图,用 VAE 编码器将其压缩为 64×64 的“潜空间图”。
- 取该图在数据集中对应的“标题” (Caption),用 CLIP 编码器将其转为“文本向量”。
- 执行“前向过程”:在“潜空间图”上添加随机“噪声”。
- 任务: 执行“反向过程”,命令 U-Net(一种因其网络结构形似字母’U’而得名的神经网络模型)“观察”这个“加噪后的潜空间图”、“时间步
t” 和“文本向量”。 - 训练目标: U-Net 必须预测出“前向过程”每一步中添加的“噪声”到底是什么。
- (注: 在实际训练中,系统会在每次循环随机挑选一个时间步
t(如t=250),U-Net 的目标是被训练成在任意一个t时刻都能准确预测出对应的噪声。)
- (注: 在实际训练中,系统会在每次循环随机挑选一个时间步
- 结论: U-Net 因此被训练成一个强大的、以“文本”和“时间”为条件的噪声预测器。
串联工作流程: 当 LDM 在进行文生图的实际工作时:
- 用户输入“提示词”和“种子”(Seed,一个系统随机生成的初始噪声图的编号,“章节四”会做详细说明)。
- CLIP 立即将“提示词”翻译成“文本向量”。
- 系统根据“种子”在潜空间中生成一张 64×64 的纯随机噪声图。
- 训练好的 U-Net 开始迭代:在每一步,它都同时“看”着 1)潜空间噪声图、2)文本向量、3)当前时间
t,然后预测出噪声,然后在当前的潜空间图像基础上将当前步预测的噪声减去。 - 循环结束后,U-Net 输出一张 64×64 的“去噪后”的潜空间图。
- VAE 解码器将这张潜空间图“解压”还原成 512×512 的最终像素图。
路径二:“像素空间”派(DALL-E 3)
DALL-E 系列采用了更“不计成本”的路径,它们选择在“像素空间”(Pixel Space,即原始的、未压缩的像素网格)中直接去噪。
DALL-E 3 的组件与训练:
DALL-E 3 的原理与 LDM 类似,但也依赖 U-Net 架构作为去噪核心。其根本区别在于“工作空间”和“翻译官”:
- 组件一(超级翻译官):GPT-4
- 作用: DALL-E 3 的“杀手锏”。它用 GPT-4 替换了标准的 CLIP 编码器。
- 工作流: 当你输入一句简单的提示词(如“戴帽子的狗”)时,GPT-4 会自动在后台将其“重写”和“丰富”成一段包含海量细节的、极其详尽的描述性段落,然后再交给“画家”。
- 训练: DALL-E 3 的“画家”模型被专门训练用来“阅读” GPT-4 输出的这种“丰富提示词”。
- 组件二(画家):像素空间 U-Net
- 作用: 这就是 DALL-E 3 的“噪声预测器”,其架构也基于 U-Net。
- 训练: 它的训练与 LDM 类似,但有一个关键不同:它不需要 VAE。它的训练任务是:给定“GPT-4 丰富后的提示词”,请直接在像素空间(或一个压缩比较小的空间)中“反向去噪”,还原出原始图像。
串联工作流程:
- 用户输入“提示词”。
- GPT-4 介入,将提示词“丰富”成一段详细描述。
- U-Net 模型介入,以这段“丰富描述”为核心引导,在像素空间中从纯噪声开始,一步步去噪,最终生成图像。
| 模型 | 工作空间 | 核心优势 | 访问性 |
|---|---|---|---|
| Stable Diffusion | 潜空间 (Latent Space) | 开源、高效、可控性强 | 可本地部署 |
| Midjourney | 潜空间 (Latent Space) | 闭源、审美调优极佳 | 闭源服务 |
| DALL-E 3 | 像素空间 (Pixel Space) | GPT-4 驱动的超强语义理解 | 闭源服务(API) |
三、AI绘画核心应用:从“文生图”到“图生图”
基于上述原理,AI 绘画工具衍生出了两大核心应用。
1. 文生图(Text-to-Image)
这是最基础的工作流。
- 输入: 文本提示词(Prompt)+ 种子。
- 准备:
- CLIP 将提示词编码为“文本向量”。
- 系统根据“种子”在潜空间中生成一张 64×64 的纯随机噪声图。
- 迭代去噪(即循环执行去噪步骤):
- U-Net 在“采样步数”(Steps)设定的次数内循环执行。
- 在每一步,U-Net 都会在“文本向量”的引导下,预测当前潜空间图中的“噪声”。
- 系统从图中减去该噪声,使潜空间图变得更清晰。
- 输出:
- 循环结束后,得到一张 64×64 的“去噪后”的潜空间图。
- VAE 解码器将其放大,还原成 512×512 的最终像素图。
2. 图生图(Image-to-Image)
图生图的流程与文生图 99% 相同,唯一的区别在于“起点”。
- 输入: 文本提示词 + 一张输入图片。
- 准备:
- CLIP 将提示词编码为“文本向量”。
- VAE 编码器将你的“输入图片”压缩成 64×64 的潜空间图。
- “破坏”(关键步骤):
- 系统故意向这张 64×64 的潜空间图上添加一定量的噪声。
- 添加“多少”噪声,由“去噪强度”(Denoising Strength,“章节四”会做详细说明)参数控制。
- 迭代去噪: U-Net 从这张“半噪声图”开始(文生图是从一张由“种子”纯随机生成的噪声图开始去噪,这就是核心区别),在新提示词的引导下,执行去噪循环。
- 输出: VAE 解码器将最终的潜空间图还原成像素图。
这样既保留了参考图的部分信息,又朝着提示词指引的方向生成了一张全新的图。
四、生图时,五个人为可控的关键控制参数
1. CFG Scale(引导强度)
这是实现“文生图”最关键的技巧之一,全称为“无分类器引导”(Classifier-Free Guidance)。它解决了“AI 如何才能严格听从提示词”的问题。
在 U-Net 去噪的每一步,模型实际上会计算两次:
- 无条件预测(Unconditional): 在忽略提示词的情况下,预测“噪声”。(这代表了模型眼中“一张普通、好看的图”应该是什么样)
- 有条件预测(Conditional): 在遵循提示词的情况下,预测“噪声”。
CFG 的魔法在于,它不做二选一,而是进行一次精妙的“向量计算”(即在数学空间中对“方向”和“强度”进行加减):
- 在我们章节一中的“回家地图”比喻中,
- “无条件”箭头 指向“家”(流形)的平均中心(一个所有图像的模糊平均体)。
- “有条件”箭头 指向“家”中你想要的特定区域(例如“猫”所在的区域)。
CFG Scale 这个参数,控制的就是以下公式中的 Scale 值:
最终的去噪方向 = [无条件] + ([有条件] - [无条件]) * Scale
这个 ([有条件] - [无条件]) 的差值,就是那个纯粹的、指向“猫”这个“概念本身”的向量。你设置的 Scale 值,就是在放大这个“概念”的强度。
- 低 CFG(如 3): AI 更有“创意”,自由发挥空间大,但可能不太“听话”。
- 高 CFG(如 12): AI 会更“严格”地遵循你的提示词(概念强度被放大),但过高可能导致图像色彩过度饱和或失真(用力过猛)。
- 默认值(如 7): 通常是“创意”与“遵循”的最佳平衡点。
2. Denoising Strength(去噪强度)
这是图生图的灵魂参数。如“章节三”所述,它控制着对原图的“破坏”程度,即在步骤 3 中添加了多少噪声。
- 低强度(如 0.3): 只添加少量噪声。AI 会在很大程度上保留原图的构图、色彩和结构,只根据新提示词做微调。
- 高强度(如 0.8): 添加大量噪声,原图信息几乎被“淹没”。AI 将获得极大的自由度,基本根据新提示词重新创作,只模糊地保留原图的构图。
3. Sampling Steps(采样步数)
即“反向去噪”的迭代次数。这不仅仅是“打磨次数”,每一步都对应着一个不同的“噪声水平”(时间步 t)。
U-Net 被训练成在不同噪声水平下有不同行为:
- 在高噪声时(早期步骤): AI 的注意力集中在恢复图像的“粗略结构”(例如“这个人是站着的”)。
- 在低噪声时(后期步骤): AI 的注意力转移到绘制“精细细节”(例如“這個人的眼睛是蓝色的”)。
因此,步数太少(如 10 步),AI 可能在“画完结构”后就停止了,导致细节不足。而超过一定阈值(如 50 步)后,质量提升会递减,计算时间则会线性增加。
4. Sampler Method(采样方法)
如果你使用过“Stable Diffusion WebUI”,可能在注意到了 Euler a, DPM++ 2M Karras 等选项。这就是“采样器”,即“如何”从第 t 步的噪声图,计算出第 t-1 步的图的数学公式。
- DDIM / DDPM: 扩散模型的“元老”算法,DDIM 更快且结果确定。
- Euler / Heun: 经典的常微分方程(ODE,即 Ordinary Differential Equations,一种用于预测连续变化的数学工具)求解器,速度快,有时更具“创意”。
- DPM++ / DM 2: 先进的求解器(DPM 指 Diffusion Probabilistic Models),通常被认为能在最少的步数内(如 20-30 步)达到极高质量,是目前的主流选择。
选择不同的采样器会显著影响图像的最终风格和生成速度。
5. Seed(种子)
即“伪随机数生成器”的起始编号。这个数字本身没有意义,但它唯一地决定了初始噪声图的具体图案。
电脑无法创造“真随机”,只能通过一个算法(伪随机数生成器)来模拟。给定一个“种子”作为算法的“钥匙”,它便会生成一套“看起来随机”的数字序列。这个“数字”的来源通常有两种:
- 软件随机分配: 默认情况下,种子值通常设为 -1。这是一个特殊指令,告诉软件:“请你帮我随机挑一个数字(如
2345678)作为本次生成的‘钥匙’”。这就是为什么你每次点击“生成”,都会得到一张构图完全不同的新图片。 - 用户手动指定: 当你得到一张满意的图后(软件会显示它所用的种子号,如
2345678),你可以在下次生图图片时手动将种子设为这个数字来“锁定”它。
总结:
- 随机种子(-1): 允许你“抽奖”,每次都从一个随机的“钥匙”开始,生成新的图案。
- 固定种子(如
2345678): “锁定”初始噪声图案。这能保证初始噪声图永远不变,此时你再微调提示词(如从“红车”改为“蓝车”),就可以只改变图像的局部内容,而保持整体构图一致,是进行可控创作的关键。
学习资料推荐:


